Identifying 'good' photographs
I use deep learning to try identify which pictures I’ve taken are good (using a loosely defined version of ‘good’). The resultant convolutional neural network (CNN) performs well (0.81 AUC), helped me identify some of my own biases, and seems like a fairly interesting start for more analysis.
Overview
Applying deep learning to image recognition is not new; more recently though, deep learning has been used to rate image aesthetics (e.g., Lu) and very recently, there’s been an uptick in using deep learning algorithms to replace photographers (e.g., Fang and Arsenal[1]). I attempted something similar, albeit hugely simplified myself, largely as a deep learning exercise that was more interesting than tweaking the architecture of existing CIFAR-10 recognition CNNs.
Using mostly my own photographs, my system was able to identify the photos that I decided were ‘good’ (read: not terrible). The results were ~71% accurate (with an unbalanced test set) and had an AUC of 0.81, as shown below.
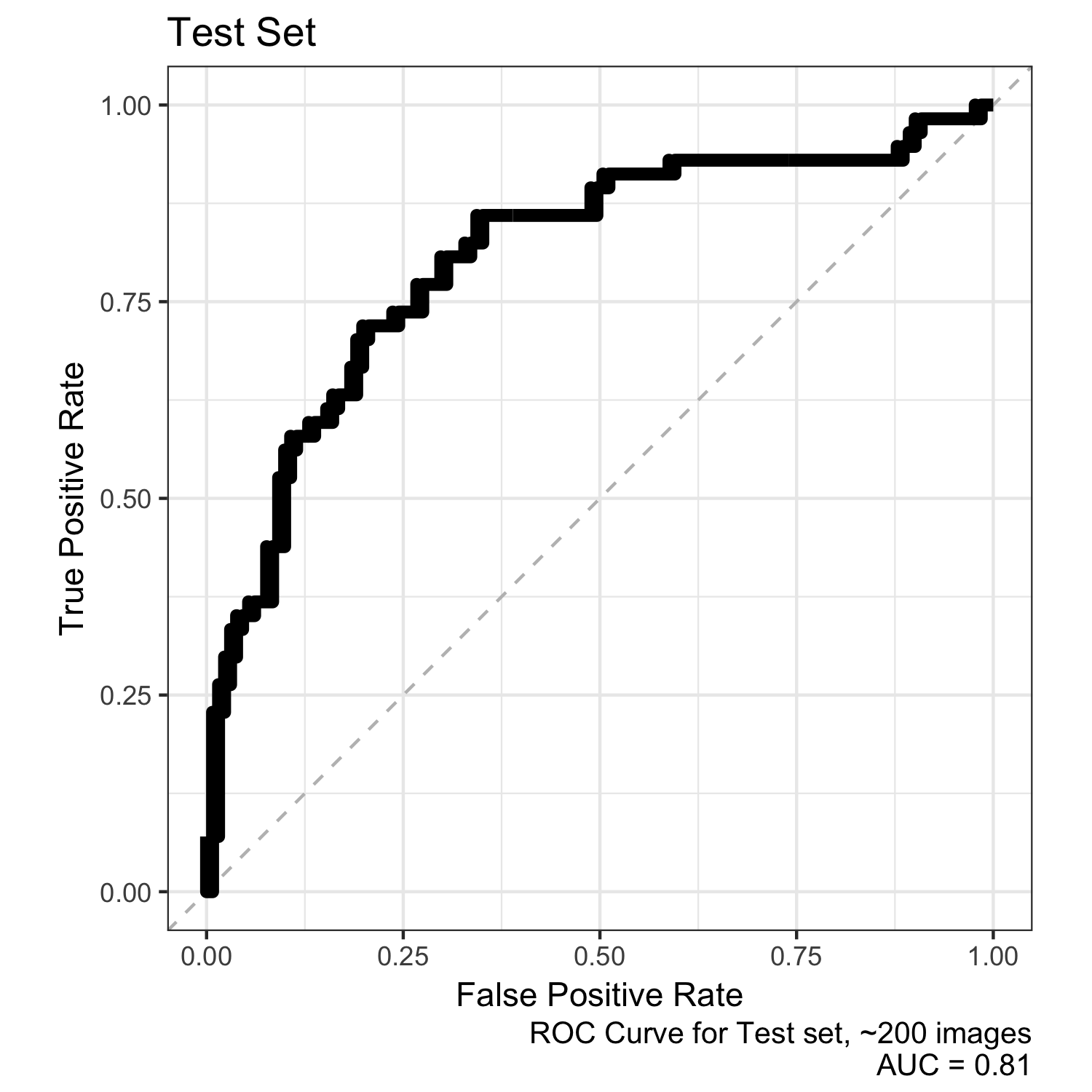
Data
Here’s where things start to get interesting. As a (digital hoarder) well-organized individual, I maintained copies of most of the photos I’ve taken on recent trips, having organized them into ‘good’ and ‘bad’ folders. I’m not a good photographer, so my usual method is to capture a bunch and hope that I get a few decent photos by sheer chance. I pulled the photographs from three trips I’ve taken within the past three years. This netted me 1,849 photos, 438 of which I thought were ‘good’. I incorporated an additional 111 photos taken by others on these same trips to net 549 ‘good’ photos.
Data Issues
Samples
This is a pretty small data set for deep learning applications. To account for this, I strove to minimize the total number of tunable parameters, and ended up with ~47k (compared to ~60M for AlexNet and ~140M for VGGNet). While this reduced my maximum potential performance and flexibility, it helped deal with the relatively low number of samples.
Unbalanced Classes
Roughly 3/4 of the images I had were classified as ‘bad’. I sampled from the training set with replacement and oversampled the ‘good’ photos to account for this.
Varying Image Sizes
I resized images to 480px wide, but maintained their original aspect ratio. This caused two issues:
- The model would have to handle differenly sized images. I dealt with this by introducing a global average pooling layer after before a fully connected (output) layer. I don’t think this is an entirely conventional use of the global average pooling, but architecturally allowed me to handle various-sized images.
- As a pure data-formatting issue, the various sizes constrained how I constructed batches. That is, all batches would need to be of the same dimensions. I randomly sampled images from the training set with replacement to construct batches, but that means that many batches ended up being repeats of the same image (e.g., I only had 1 480x544 image in my training set). To prevent this oversampling from influencing the model too much, I used a relatively small batch size (4 photos per batch).
Biased Data Set
I labeled all the images myself, prior to starting this project, over a relatively short amount of time. The ‘good’ images were generally corrected/adjusted in lightroom, whereas the ‘bad’ images generally were not. This created a biased data set, which certainly makes this model less generally applicable. It does make the problem much easier though – it is presumably easier to systematically identify my preferences than some abstract notion of ‘good’ vs ‘bad’ photos.
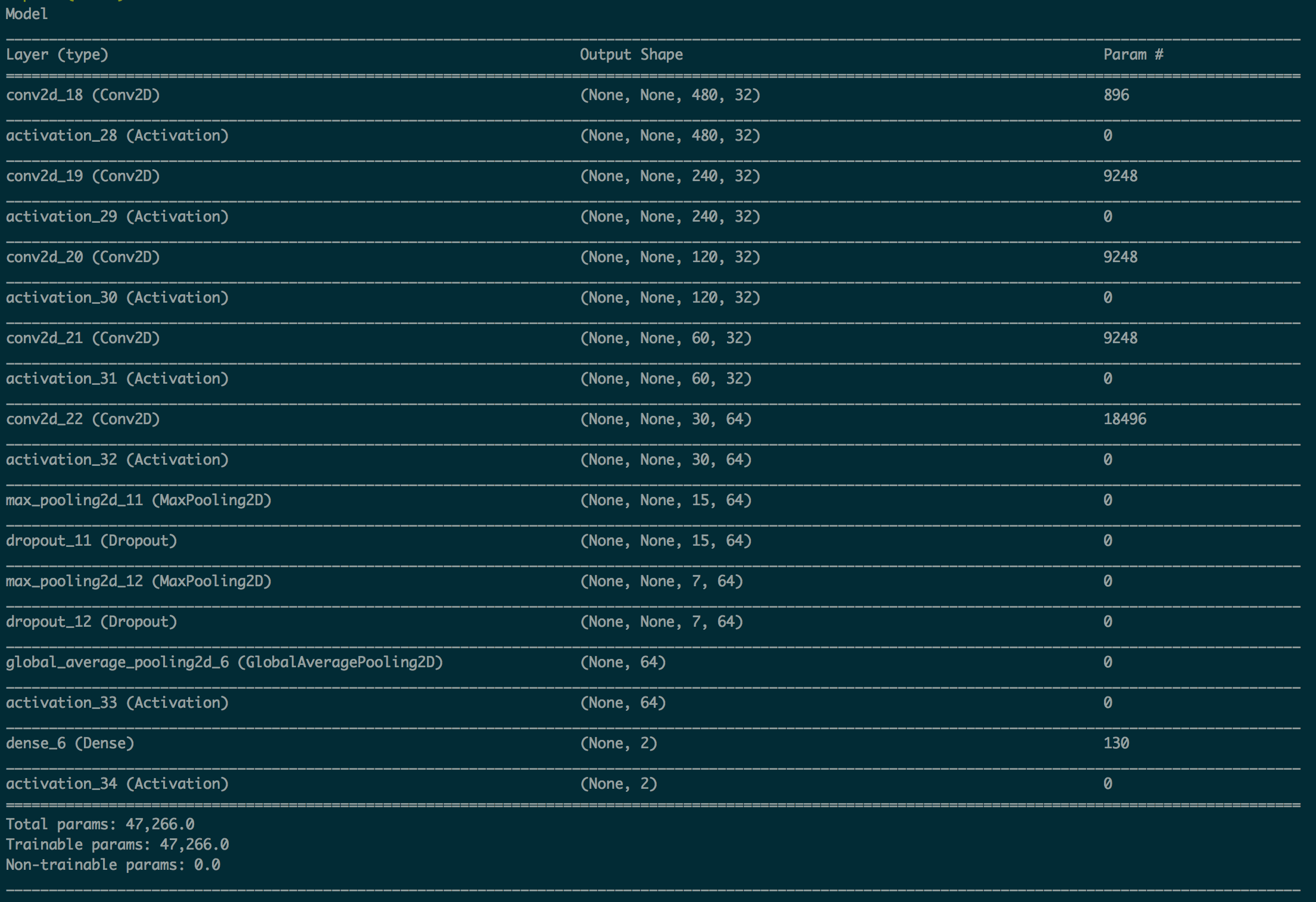
Model
The model is a fairly straightforward convolutional neural network (CNN). I chose to use several convolution layers to allow the network to have a broader (effective) visual field without increasing the number of parameters too much.
Sorry for the crummy screenshot; I’m working to incorporate a more clear diagram.
Performance and Discussion
The plot below shows how the performance changed over time. Because of the small batch size, I’m only showing the moving average of the training set performance; otherwise the data would be far too noisy. As you can see, the validation set performance bounces around quite a bit (likely due to training on small batches that weren’t simple random samples).
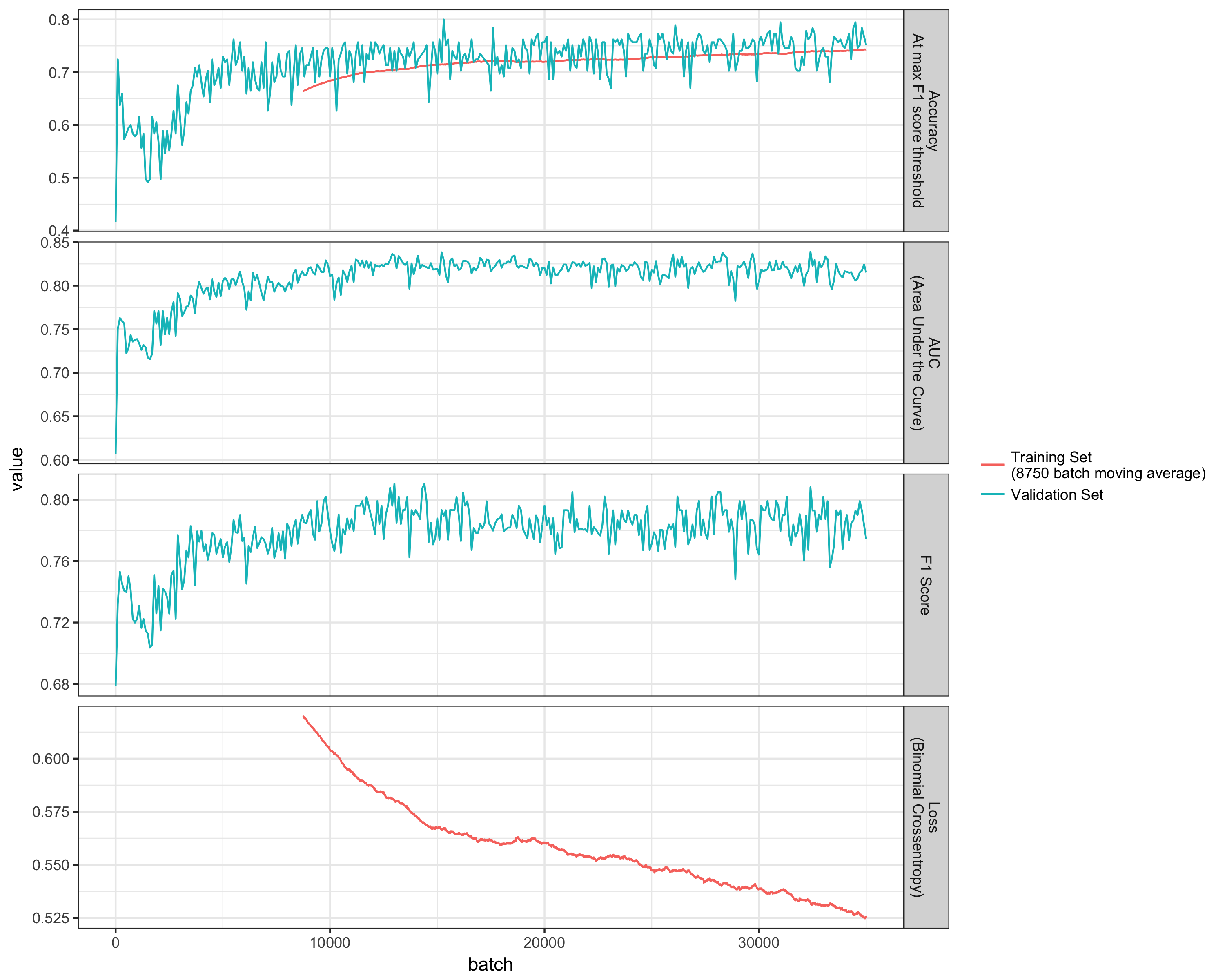
The performance on the validation data set starts to plateau around batch 10,000, but appears to still be improving with more batches; i.e., this model is probably underfit. The performance on the training set is improving, and would be expected to continue to improve (as the model would eventually start to overfit).
As a validation, I manually inspected the test set performance. I expected it to identify my own biases (e.g., landscapes > portraits, wide angle > tight angle, a solid horizon at the bottom 1/3rd, etc). Some of these are shown below; the first thirteen are high-scoring images, the last twelve are low-scoring images; images outlined in red are misclassified. I redacted potentially identifiable faces for privacy and shrank the images.

The model appears to have picked up on some of my biases (many of which were unknown to myself). Clearly I’m biased towards blue, white, and green, I seem to prefer non-flat horizons, and at least a few people in the photo.
Next Steps
I worked on this project entirely for fun, so there are still quite a few areas I’d like to explore. I’m most interested in better understanding what the network is ‘thinking’; i.e., whether it has identified simple heuristics (like color and regions of contrast). To that end, I’m planning to apply deep dream to this to try and better understand what it’s seeing (and whether I can transform ‘bad’ photos into ‘good’ ones that simply).
There’s been some interesting work done on broader photo sets (e.g., the Ava/DPChallenge photo libraries), and I am curious to try those out – to try applying this trained model to those data sets, and conversely train on those data sets to evaluate my own pictures.
I performed this work locally on CPU using a combination of R, Keras, and Tensorflow. I had very little free memory, so I kept most of the data on disk and found that it wasn’t a huge hit to performance. To work with these larger data sets, I’ll likely move to a cloud GPU-based solution (e.g., AWS) and maybe even try to use spot instances, which would make the engineering somewhat more of a challenge (i.e., moving to/from disk will become a significant handicap, and it’ll need to be more fault tolerant/scalable).
[1]From what I can tell, Arsenal uses deep learning to recognize (objects in) the scene and then applies a set of expert-defined parameters in response to water/forests/etc. If well done, that’s certainly nothing to sneeze at, but it sounds like a different implementation of built-in scene recognition auto mode that already exists in many cameras. Happy to be corrected if I’m wrong though.
Mini update: I received a couple requests to see the code used to do this. I’ve posted it on github (it’s very unpolished).